Colleagues
[Apologies for the length of this email...]
The chairs would like to suggest creating a new NWI for the "geofeed:"
attribute and suggest the following draft Problem statement and
Solution definition. If there is agreement on this the RIPE NCC will
do an impact assessment including legal review and summary of what the
other RIRs are doing.
There has already been quite a discussion in the WG on this issue with
a lot of support. So hopefully we can reach a consensus quickly, at
least on setting up the NWI and starting the impact assessment. Having
read the latest draft IETF docs, there are some outstanding questions.
Comments and changes are welcome...
cheers
denis
co-chair DB-WG
Problem statement
Associating an approximate physical location with an IP address has
proven to be a challenge to solve within the current constraints of
the RIPE Database. Over the years the community has chosen to consider
addresses in the RIPE Database to relate to entities in the assignment
process itself, not the subsequent actual use of IP addresses after
assignment.
The working group is asked to consider whether the RIPE Database can
be used as a springboard for parties wishing to correlate geographical
information with IP addresses by allowing structured references in the
RIPE Database towards information outside the RIPE Database which
potentially helps answer Geo IP Location queries
The IETF is currently discussing an update to RPSL to add a new
attribute "geofeed: url". The url will reference a csv file containing
location data. Some users have already started to make use of this
feature via the "remarks: geofeed: url". It is never a good idea to
try to overload structured data into the free format "remarks:"
attribute. This has been done in the past, for example with abuse
contact details before we introduced the "abuse-c:" attribute. There
is no way to regulate what database users put into "remarks:"
attributes. So even if the new "geofeed:" attribute is not agreed, the
url data will still be included in the RIPE Database.
Currently there are 24,408 INETNUM and 516,354 INET6NUM objects
containing a "remarks: geofeed: url" attribute in the database. These
have 7,731 distinct values in the INETNUMs and 1,045 distinct values
in the INET6NUMs.
Solution definition
Implement a new "geofeed:" attribute according to the IETF's
definition. Although the IETF has not yet concluded discussions on
this attribute we can still implement it in the RIPE Database RPSL
data definition. The RIPE Database already has many local differences
to the RPSL standard. As expressed in the Problem statement, users are
already using the geofeed data by overloading the "remarks:"
attribute. That is a dirty hack which should be avoided.
An invalid formated url will be a syntax error.
The RIPE NCC will perform a one time conversion of the existing data
to convert "remarks: geofeed: url" to "geofeed: url".
If an update then contains a "remarks: geofeed: url" attribute, the
update will be successful and the response should include an
appropriate Warning message. At some point in the (near) future, this
could be changed to an update failure as a syntax error.
An update containing a "geofeed:" and a "remarks: geofeed:" attribute
or more than one "remarks: geofeed:" will be a syntax error.
The resource holder should be able to create, modify, delete the
"geofeed:" attribute in allocation objects.
Questions:
-Should the database software do any checks on the
existence/reachability of the url as part of the update with an error
if the check fails?
-Should the RIPE NCC do any periodic repeat checks on the continued
existence/reachability of the url?
-Should the RIPE NCC do any periodic checks on the content structure
of the csv file referenced by the url?
-Should the Solution definition define how this will be adopted into
RDAP or should we simply ask the RIPE NCC to define this in their
impact assessment?
-The RIPE Database contains hierarchical address space objects. Should
it be acceptable for "geofeed:" attributes to exist at multiple levels
within a specific hierarchy?
-Suppose a geofeed csv file referenced by a /16 INETNUM object
contains location data for the whole /16. Then a more specific /24
INETNUM object references another geofeed csv file that contains
conflicting location data for this /24. Should this be a concern for
the RIPE Database?
-Should geofeed data be inherited? If you query for a /24 that does
not contain a "geofeed:" attribute, but a less specific /16 does
contain a "geofeed:" attribute, should this data be returned? In other
words could it be used in a similar way to "abuse-c:"?
-Thinking ahead to how people will actually deploy this data and what
short cuts they could make. It is said that when reading a geofeed csv
file, consumers of the data should ignore all data within that file
not directly concerning the address space queried in the RIPE
Database. Could you therefore create a single csv file with location
data for all your address space and reference the same file in all
your RIPE Database address objects? The address space owner could rely
on the data consumer to pick out the correct piece of data for the
relevant address space. The manager of the csv file then only has to
work with one file. If this is possible and does happen (which the
IETF doc 'Finding geofeeds' seems to suggest is possible for unsigned
geofeed data), would it therefore make sense to apply "geofeed:"
hierarchically as with "abuse-c:"? Allow a single, default "geofeed:"
attribute in the ORGANISATION object to be applied to all that
organisations address space, with the option of specific localised
"geofeed:" attributes in address space objects. That could be a neater
solution, and easier to setup, than applying thousands of references
to the same geofeed file at a more specific level in the database.
-Relating to the above 3 questions, should geofeed data only be
considered applicable if returned by a specific geofeed locater
application which takes into account the hierarchical nature of
address space in the database? Otherwise do the standard database
query mechanisms have to take into account this hierarchy and locate
the most specific "geofeed:" attribute from the less specific objects?
-Should/could the RIPE Database return the csv file as part of the
query? If so should the file be cached (for how long?) to avoid too
many downloads?
-Should we only allow HTTPS urls? (Which the IETF doc 'Finding
geofeeds' seems to suggest)
-Should the RIPE NCC go ahead and implement this now, with our own set
of RIPE rules? Or should we try to coordinate this and agree a set of
common rules between all the RIRs before any deployment in the RIPE
Database?
-For the legal review, there are 2 statements in the IETF doc 'Finding
geofeeds' which may be of concern:
*[RFC8805] geofeed data may reveal the approximate location of an IP
address, which might in turn reveal the approximate location of an
individual user. Unfortunately, [RFC8805] provides no privacy
guidance on avoiding or ameliorating possible damage due to this
exposure of the user. In publishing pointers to geofeed files as
described in this document the operator should be aware of this
exposure in geofeed data and be cautious. All the privacy
considerations of [RFC8805] Section 4 apply to this document.
*It is significant that geofeed data may have finer granularity than
the inetnum: which refers to them.
It is clear that the RIPE NCC cannot prevent this data being
referenced by objects in the RIPE Database. It is already being
referenced from "remarks:" attributes. Perhaps the RIPE NCC should
require (as part of their service agreement) that it's members obtain
written consent from their customers to publish this location data, or
at least inform the customers in writing that it will be published.
Also, although RFC8805 says postcode is deprecated it is still
provided for in the csv files. So anyone can still enter location data
to this detail.
-The IETF doc 'Finding geofeeds' suggests that geofeed information
'will be' available in bulk accessed whois data. In view of the
privacy concerns above, is this likely?
-The IETF doc 'Finding geofeeds' says "To minimize the load on RIR
whois [RFC3912] services, use of the RIR's FTP [RFC0959] services
SHOULD be the preferred access." Is the RIPE NCC expected to download
all the geofeed files and make them available through their FTP
service?
-The IETF doc 'Finding geofeeds' states that consumers of the geofeed
data MUST NOT access this data in real time via the RPSL servers 'too
frequently' or at 'magic times like midnight'. Some users will do
whatever they want to do if they are able to do, regardless of any
statements to the contrary. Should the RIPE NCC enforce such access
rules by some means?
References
The IETF doc 'Finding geofeeds':
https://datatracker.ietf.org/doc/draft-ietf-opsawg-finding-geofeeds/?includ…
geofeed file format:
https://www.rfc-editor.org/rfc/rfc8805.html
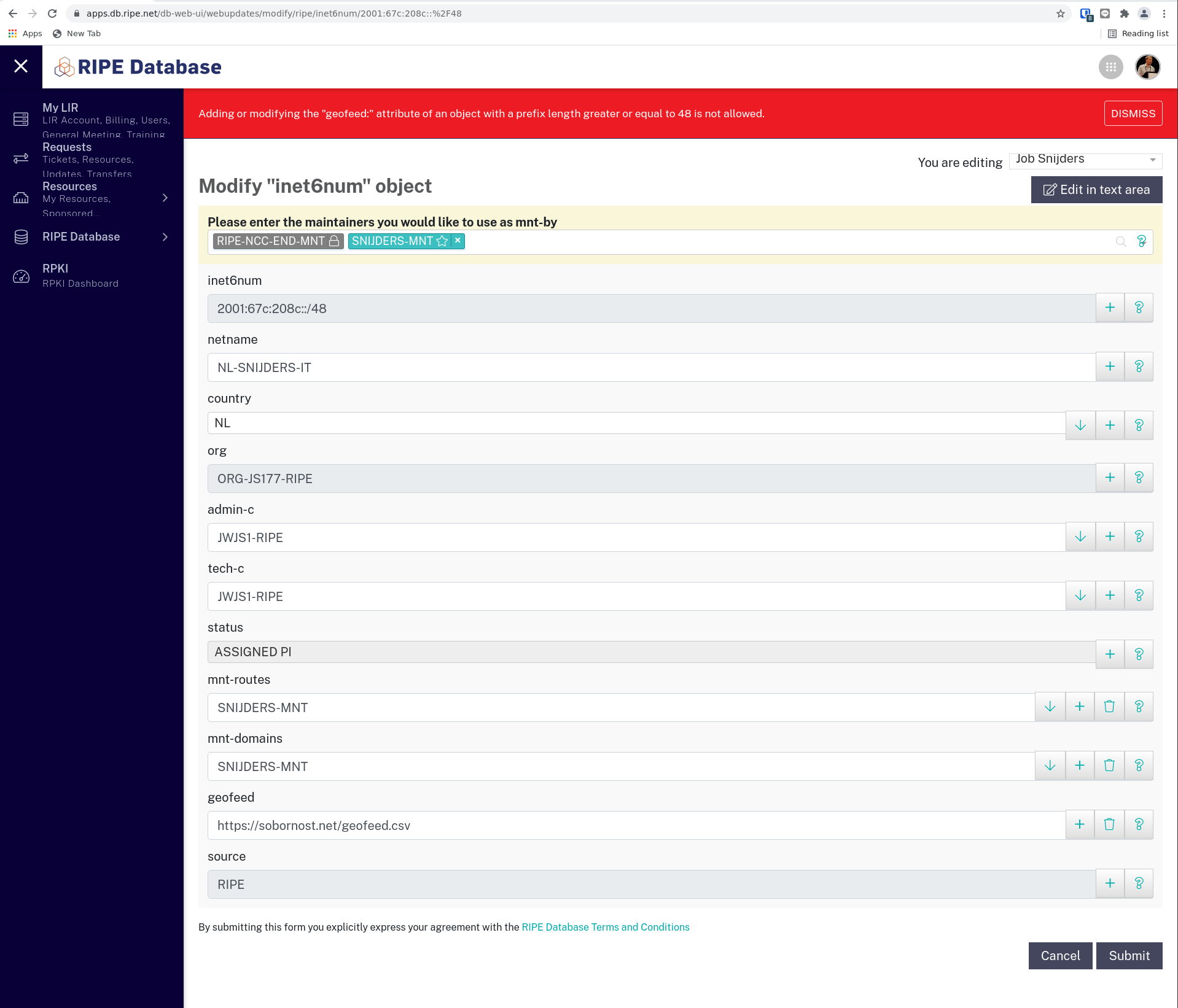
Dear all,
Like all good netizens, I tried to align information I publish in the
RIPE database to reality, but there is an obstacle:
https://sobornost.net/~job/geofeed.png
"""Adding or modifying the "geofeed:" attribute of an object with a
prefix length greater or equal to 48 is not allowed."""
No such restriction exists if you use the 'remarks: Geofeed' approach,
as demonstrated here:
$ whois -h whois.ripe.net 2001:67c:208c::/48 | grep Geofeed
remarks: Geofeed https://sobornost.net/geofeed.csv
I appreciate concerns about privacy, but I'm not wholly convinced
restricting /48s from having a proper 'geofeed:' attribute is the best
path forward.
How does the working group feel about this restriction? Is it useful?
Should it be lifted? If the latter, what would be the process?
Kind regards,
Job
Dear RIPE DB wg,
The RDAP for querying ip and network information on rdap.db.ripe.net is really useful.
Currently you support the rdapConformance level "rdap_level_0" and this is missing the CIDR or Prefix Information about the Length/Mask.
Other RIR have implemented a rdap conformance level "cidr0" for this:
* https://rdap.arin.net/registry/ip/9.9.9.9
* https://rdap.apnic.net/ip/1.1.1.1
with the desired information:
"cidr0_cidrs": [
{
"v4prefix": "1.1.1.0",
"length": 24
}
]
Information about the Origin ASN is also available by arin with "arin_originas0", which is also very helpful, but the format seems to be arin specific and not standardized.
May I suggest to also implement the cidr0 level, or even additionally the "origin as" for the RIPE DB RDAP?
Kind regards,
Benjamin
Dear colleagues,
We have now published our Q1 2022 planning for the RIPE Database:
https://www.ripe.net/manage-ips-and-asns/db/quarterly-planning/
This is the second quarterly plan we have published. The previous plan for Q4 2021 is also available so you can see how we progressed and see what was completed and what will continue in Q1 2022:
https://www.ripe.net/manage-ips-and-asns/db/quarterly-planning/archived-pla…
If you have comments or questions around our plans, we hope you'll discuss with us on the list or you can always contact us directly at ripe-dbm(a)ripe.net.
Regards,
Ed Shryane
RIPE NCC




{kind=link}